Dateiverarbeitung
Lassen Sie Dokumente sich selbst lesen und strukturieren, sodass manuelle Eingabe verschwindet.
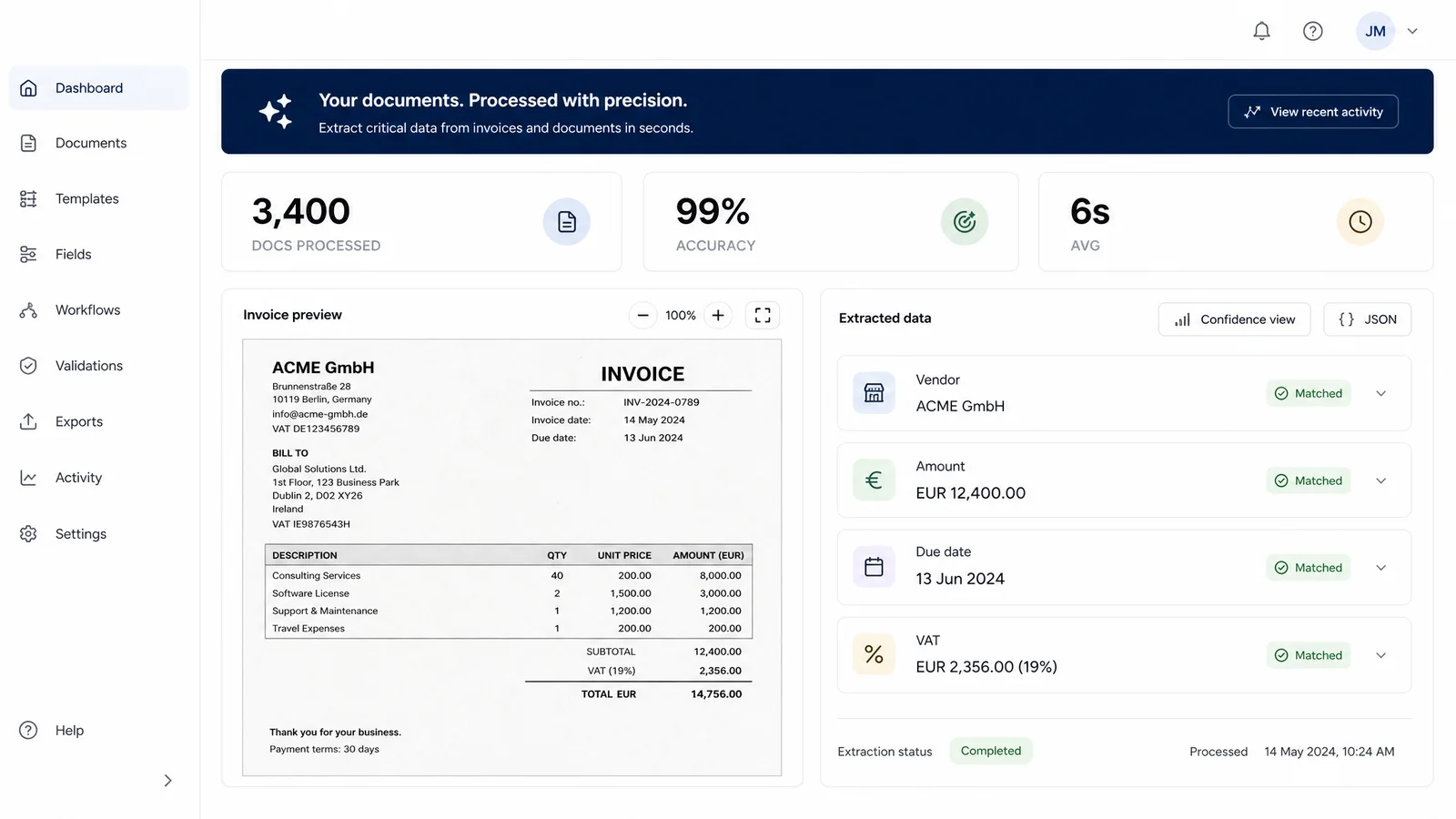
Rechnungen, Verträge, Belege, Formulare: Die meisten werden noch von Hand in ein System getippt. Wir bauen Pipelines, die Dokumente automatisch lesen, die wichtigen Felder herausziehen, sie strukturieren und Ihnen saubere, sofort nutzbare Daten übergeben.
Das funktioniert auch bei gescannten und fotografierten Dateien, über OCR, also das Erkennen von Text aus einem Bild. Das System validiert, was es extrahiert, markiert alles, was auffällig wirkt, und liefert das Ergebnis als Tabelle, als Excel- oder CSV-Datei oder direkt in Ihr System.
Was es macht
OCR
Text aus Scans, Fotos und PDFs lesen, sodass selbst aus einem Handyfoto eines Belegs maschinenlesbare Daten werden.
Extraktion
Die wichtigen Felder, Betrag, Datum, Lieferant, Positionen, automatisch aus jedem Dokument herausziehen, unabhängig vom Layout.
Strukturierung
Losen Dokumenteninhalt in saubere, einheitliche Datensätze verwandeln, bereit für Ihre Datenbank, Buchhaltung oder Tabelle.
PDF zu Excel oder CSV
Stapel von PDFs in strukturierte Tabellen umwandeln, sodass aus einem Berg von Dateien in einem Durchlauf ein nutzbarer Datensatz wird.
Validierung
Das System prüft extrahierte Daten gegen Regeln und erwartete Formate und markiert alles Auffällige für eine kurze menschliche Prüfung.
Klassifizierung und Ablage
Dokumente werden erkannt und automatisch in die richtige Kategorie und den richtigen Ordner sortiert, sodass nichts verloren geht oder falsch abgelegt wird.
Die Finanzabteilung erhält 500 Lieferantenrechnungen im Monat. Statt jede einzeln einzutippen, liest die Pipeline jede Datei, extrahiert Betrag, Datum und Lieferant, validiert die Summen, markiert zwei, die nicht aufgehen, und legt den Rest in einer sauberen Tabelle ab, bereit für das Buchhaltungssystem.
Was Sie bekommen
- Dokumente automatisch gelesen und strukturiert
- Manuelle Eingabe entfällt
- Daten sofort nutzbar, in Ihrem Format
- Funktioniert bei Scans und Handyfotos, nicht nur sauberen PDFs
- Fehler früh erkannt durch eingebaute Validierung
Fragen
Funktioniert es bei gescannten oder fotografierten Dokumenten?
Was, wenn ein Dokument falsch gelesen wird?
Kann es verschiedene Rechnungslayouts verarbeiten?
Hören Sie auf zu tippen, was eine Maschine lesen kann
Buchen Sie einen Termin, und wir zeigen, wie sich Ihre Dokumente selbst strukturieren könnten.